
XLSTM vs LSTM: How the new LSTM Scale Sequence Prediction without Attention?
xLSTM: Extended Long Short-Term Memory (NeurIPS 2024)

Table of Content

Why LSTM?
Sequential data is a type of data where the order of the elements matters. Examples include time series (e.g., stock prices, weather data), natural language text, and audio signals. Processing sequential data requires models capturing the dependencies between elements—, i.e., a memory that can store, process and retrieve the elements over time.
Recurrent Neural Networks (RNNs) were among the first deep learning models designed to handle sequential data. They use the same set of weights at each time step, allowing them to process sequences of arbitrary length. For example, at a given timestep t, a classic RNN forward pass reads:
where σ is the activation function, ht is the hidden state or vector memory encoding input xt, ot is the output at step t.

RNNs are powerful because they are Turing complete, meaning they can simulate any Turing machine given the right parameters, enough time, and resources—they can compute any computable things [1]. However, RNNs face the vanishing/exploding gradient problem, where gradients can become exponentially small or large during backpropagation, making it difficult to learn long-term dependencies. Broadly speaking, the gradient backpropagated from the loss to a neuron at a past timestep is influenced by the product of multiple Uh matrices, which can lead to exponential decay or explosion (see at the end of the post for more details).
👀 This issue arises naturally from the recursive dependence between ht and ht-1, making learning infeasible for long time steps (vanishing gradients) or leading to unstable computations with overflow and NaN values (exploding gradients). The only way to ensure this does not occur is to fix Uh=1, but this restricts the flexibility needed to adjust the hidden state dynamics, e.g., removing unimportant states, which is essential for various tasks.
Several factors exacerbate this problem:
Non-linear activation σ: Their derivative changes faster, making vanishing or exploding happen faster. σ like sigmoid encourages vanishing problems because its output is between [0,1] and its derivative is between [0,1/4]. Changing activation may relieve these issues but does not change the nature of vanishing/exploding.
t: The exponential rate depends on t; as t increases, vanishing or exploding occurs more rapidly. Artificial solutions like truncating sequence length or training on fixed-length inputs are practical, but they fail to address scenarios where learning depends on distant input timesteps.
Unormalized input/output: Without normalization, the system is easier to explode with big values. Normalization and gradient clipping can help mitigate exploding gradients to some extent, but it comes at the cost of reduced learning flexibility.
👀 The gradient vanishing/exploding problem can occur in deep neural networks with many layers, but it is generally less severe than in RNNs. This is because each layer in a deep neural network has its own unique weight matrix. When multiplying the weight matrices, the product is less likely to become extremely large or small, reducing the risk of gradient issues.
Long Short-Term Memory (LSTM) was introduced to address the limitations of RNNs. LSTMs incorporate memory cells and gates that selectively store and retrieve information, separating memorization and computing. The key idea is that instead of using a fixed weight to update the hidden state, we use a dynamic weight—referred to as a gate—generated by the current input. When the gate is set to 1, no gradient issues arise (constant error carousel), allowing the backpropagation to proceed smoothly and enabling the learning of other network parameters. The gate is adaptable to the data, allowing it to selectively turn off and ignore irrelevant inputs that could otherwise disrupt the output.
Based on this idea, Hochreiter and Schmidhuber proposed the original LSTM [2] as follows:

The original version uses a scalar memory cell c and vector weights wz, wi, wf, and wo. Later, it can be easily extended to a vector memory cell c and matrices Wz, Wi, Wf, and Wo. The input and cell state are normalized by φ and ψ, respectively, which can be implemented as tanh functions.
LSTM's gating mechanism allows the network to manage long-term dependencies by controlling the flow of information. For example, in language modeling, the forget gate can discard earlier context when it's no longer relevant, like forgetting previous sentences when focusing on a new clause. The input gate decides what new information to store, such as remembering a keyword that influences the next prediction. The output gate ensures that the current state, like the current topic of conversation, is passed to the prediction.
❌ While LSTMs mitigate the vanishing gradient problem through their gating mechanisms, they can still suffer from gradient issues, especially over very long sequences. The gates themselves can cause the gradient to vanish. When outputting values close to 0, it can lead to diminished gradient flow. And there is no guarantee on the quality of the gate value.
❌ Even more concerning is that the gate relies on previous hidden states, which can lead to gradient issues when learning the gate parameters and result in slower computation.
Addressing LSTM Limitations
Over the years, numerous versions and improvements to LSTM have been developed. The latest innovation, xLSTM [3], is an advanced variant of LSTM designed to improve performance and efficiency by incorporating matrix-based cells and optimizing gate computations, enabling it to perform well in tasks typically handled by attention-based models, without quadratic complexity. In particular, it introduces several new tricks:
New Gates: The sigmoid function limits the range of gate values to [0, 1], which can restrict the flow of information. Conversely, the exponential function allows for a wider range of values, potentially enabling the LSTM to avoid vanishing issues.
New Normalizer: Exponential activation gates can generate large values that lead to overflow, requiring a more robust normalizer. This new dynamic normalizer works by dividing the sum of the product of the input gate at the current time step with all future forget gates.
Matrix Cell State: By increasing the dimensionality of the cell state, making it a matrix, the LSTM can store more information, potentially improving its performance on tasks that require long-term memory.
Simplified Recurrence: LSTMs' recurrent nature can limit their parallelization potential. By simplifying the recurrence relation, more efficient parallel processing may be enabled.
One common feature is the presence of new gating functions, which are carefully selected as:

Interestingly, although forgetting gate ft most influences the vanishing problem, the old sigmoid gate is still recommended. The main change is in the input gate where exp() replaces sigmoid().
Other tricks are realized in 2 variants of xLSTM:
sLSTM (scalar): Trick 1, 2
mLSTM (matrix): Trick 1, 2, 3, 4
The new normalization and update rules are also referred to by the authors as new memory-mixing techniques. We will delve into the details of each variant below.
sLSTM
This variant closely resembles the original LSTM, but uses new gate functions and introduces a normalizer state that is also computed recurrently:
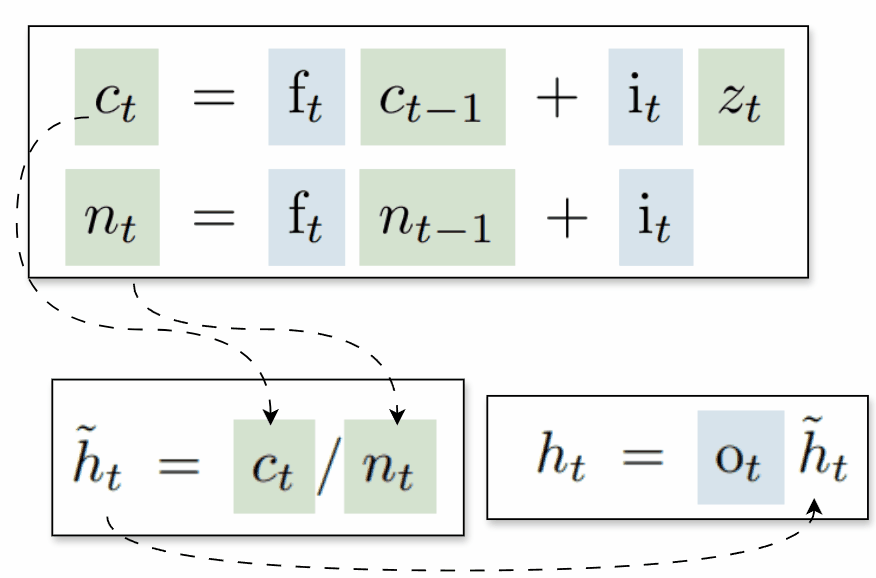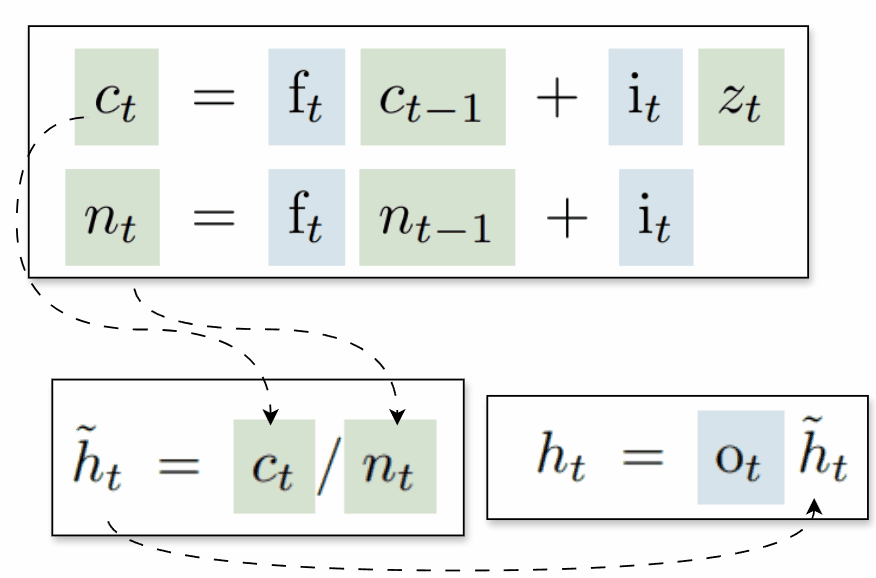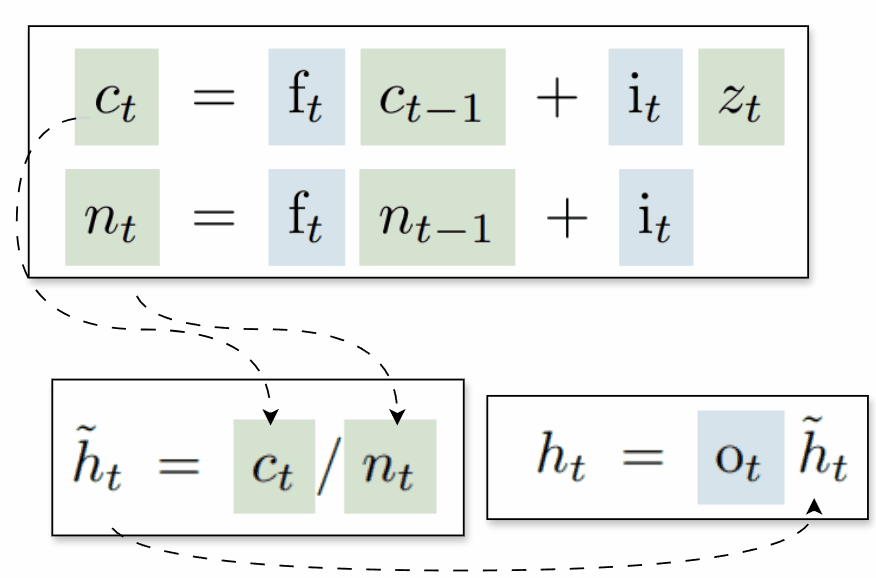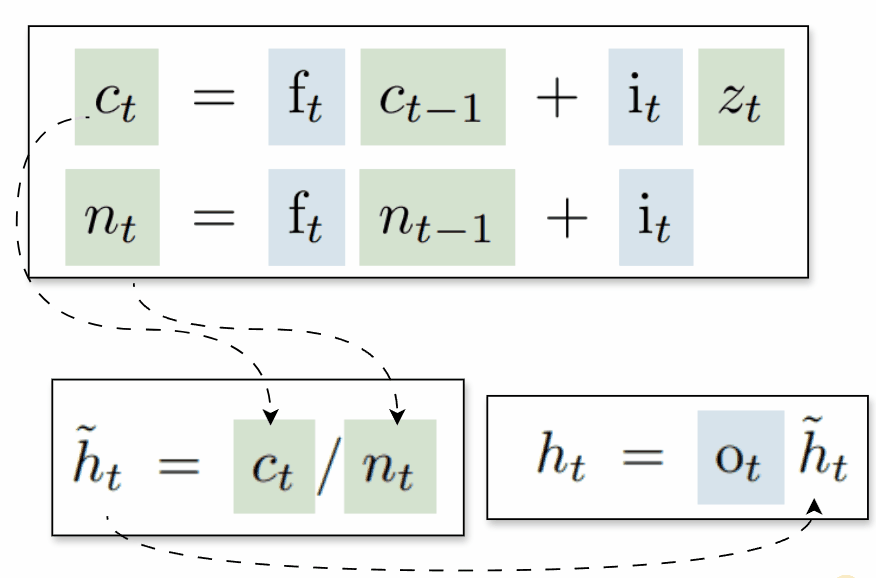
To ensure stable computation, the authors propose maintaining a stabilizer state mt, which helps prevent overflow when computing the logarithm of a sum of exponentials by subtracting the maximum value from all inputs before applying the exponent. This keeps the exponentiated values smaller and more manageable:

With any m, it is easy to show that stabilizing the gates does not change the form of LSTM:

mLSTM
A key advancement for LSTM is the use of a matrix-based cell, making it more similar to earlier memory-augmented neural networks (MANNs [4]). However, modern memory-augmented neural networks (MANNs) favor a simplified design, making them faster to train and easier to learn. Following this trend, mLSTM matrix-memory updates look simple, with cleaner normalization than sLSTM:

The cell matrix Ct is updated using linear formulation. Without the gates ft, it, this exactly like the Hebbian update rule or Covariance update rule [5]. Here, vt, kt, and qt are value, key, and query vectors resulting from the input at step t:

In addition to the matrix cell, one notable difference from the original LSTM is that the gates use exp() and do not depend on the previous hidden state ht-1:
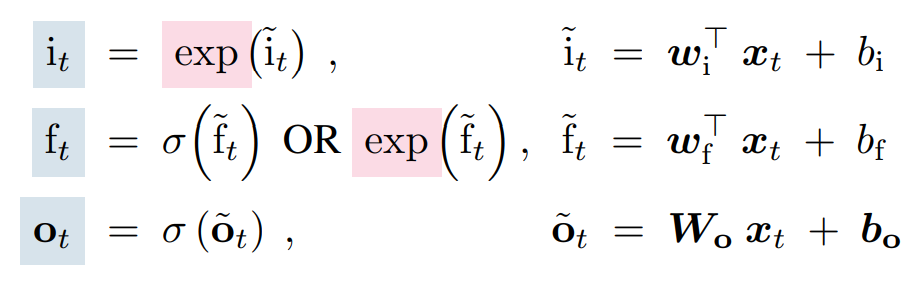
👀 The fact that the gate is computed based on the current time step limits the flexibility of LSTM, as inputs from the distant past might influence whether gates should open or close at the present step. However, this design introduces a new advantage for LSTM: parallelization (explained at the end of this post).
xLSTM Architecture
sLSTM and mLSTM are combined to build the complete xLSTM Block. We can stack multiple xLSTM blocks to build large language models (LLMs):

Compared to the original LSTM and Transformer, xLSTM brings unique benefits, as shown in the results on a toyish task:

xLSTM significantly outperforms standard LSTM and demonstrates competitive performance against Transformers, all without relying on attention mechanisms or quadratic computational complexity.
When compared to other efficient sequential models like Mamba or RWKV, xLSTM, and its variants consistently deliver better performance across a range of algorithmic tasks:

The deep xLSTM version, xLSTM[7:1], refers to a configuration where seven out of eight blocks are mLSTM-based and one is sLSTM-based, and it shows promising scaling behavior in large language model (LLM) tasks.

Appendix
Vanishing/Exploding Gradient Problem
We revisit the vanishing and exploding gradient problem in training RNNs (or deep neural networks) through Hochreiter's classic analysis [6]. Let’s consider the hidden layer of an RNN, where each neuron receives input from the previous time step. The activation of a neuron i at time t can be written as:
where fi is the activation function, and wij is the weight connecting neuron j to neuron i. neti() represents the weighted sum of inputs to a particular neuron i at time step t before applying the activation function. When backpropagating the error signal ϑ for neuron j at time t, the recursive form of computing the error signal is:
where fj′(netj(t)) is the derivative of the activation function of neuron j at time t. The error signal is proportional to the gradient ∂L/∂wij required to learn network parameters. In practical implementation, the error signal flows backward from the higher layers to the lower layers. The initial error at the output layer is determined by the difference between the predicted output and the ground-truth data.

In RNNs, this error signal gets passed through time. The key issue is when we backpropagate the error from an arbitrary neuron u at time t to an arbitrary neuron v at time t - q. This process allows us to assess how changes in the error at neuron u affect the error at neuron v. The contribution of u's error to v's error is:
Using induction, we can derive the closed form of the recursive equation for the error backpropagation as follows:
In this equation, lq=v and l0=u. lm is an intermediate neuron in the computation path at step m. n is the number of neurons of the hidden layer of the RNN. Intuitively, we can visualize the computation path as a graph where each computation node has n child nodes. Each product term represents a unique computational path of depth q extending from node u to node v, and we have n^q-1 such paths. Therefore, the error contribution of u to v is the sum of all product terms (paths).

A critical aspect of backpropagation in recurrent neural networks (RNNs) is understanding how the product of derivatives and weights behaves. Specifically, if the absolute value of the derivative of the activation function at a given time step, multiplied by the weight between the corresponding neurons |flm′(netlm(t−m))⋅wlmlm−1|, is greater than 1 for all steps, the resulting product grows exponentially as the number of time steps increases. Conversely, if this value is less than 1, the product decreases exponentially. This behavior is directly related to the well-known exploding and vanishing gradient problems encountered during the training of neural networks.
In practice, weights are typically initialized with small values, and the activation functions used, such as sigmoid or tanh, are bounded and non-linear. As a result, the likelihood of encountering vanishing gradients during training is quite high, particularly as the error signal is propagated through many layers or time steps. This issue hampers the ability of the network to learn long-range dependencies, as the gradient becomes too small to effectively update the model’s parameters. To mitigate this, alternative architectures, such as LSTM, are invented.
Parallelization of Matrix Memory Update
We explore a generalized approach to memory updates, focusing on how it can be parallelized for efficient computation. The mLSTM cell update serves as a specific instance of this broader formulation:
where ⊙ is the Hadarmard (element-wise) product. By induction, we can derive the closed form:
If Ct and Ut are independent of the previous memory states M<t, the memory updates can be computed in parallel using the unrolled equation. Specifically, the set of products {∏j=i+1Cj} can be computed in parallel using prefix product, with the time complexity of O(logt). Similarly, the summation across the terms can also be performed in O(logt) using parallel prefix sum. Since all operations are element-wise, they can be efficiently parallelized across the memory dimensions, further speeding up execution (see more in [7]).
Since mLSTM is a special case, where all elements of Ct are ft and Ut = itvt⊗kt, it can be computed efficiently using parallel computation.
References
[1] Hava T Siegelmann and Eduardo D Sontag. On the computational power of neural nets. Journal of computer and system sciences, 50(1):132–150, 1995.
[2] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997.
[3] Beck, Maximilian, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. "xLSTM: Extended Long Short-Term Memory." arXiv preprint arXiv:2405.04517 (2024).
[4] Graves, Alex. "Neural Turing Machines." arXiv preprint arXiv:1410.5401 (2014).
[5] Hopfield JJ. Neural networks and physical systems with emergent collective computational abilities. Proc Natl Acad Sci U S A. 1982 Apr;79(8):2554-8. doi: 10.1073/pnas.79.8.2554. PMID: 6953413; PMCID: PMC346238.
[6] S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Master’s thesis, Technische Universität München, 1991.
[7] Le, Hung, Kien Do, Dung Nguyen, Sunil Gupta, and Svetha Venkatesh. "Stable Hadamard Memory: Revitalizing Memory-Augmented Agents for Reinforcement Learning." arXiv preprint arXiv:2410.10132 (2024).