
Curious Agents Saga: Part 3
Beyond Surprise: Direct and Causal Exploration in Deep Reinforcement Learning

Table of Content
Reflection on Intrinsic Motivation
In the previous article, we reviewed an essential exploration framework called intrinsic motivation, which is widely used in deep RL due to its scalability. Within the framework, surprise and novelty are the medium for exploration. Regarding surprise, memory is often hidden within dynamics models, memorizing observed data to enhance predictive capabilities. This type of memory tends to be long-term, semantic, and slow to update, akin to a careful archivist meticulously preserving information.
On the other hand, novelty takes a more straightforward approach to memory. Memory is delineated here, resembling a slot-based matrix, a nearest neighbor estimator, or a simple counter. This memory is typically short-term, instance-based, and highly adaptive to environmental changes, acting more like a dynamic and responsive agent ready to adjust to new inputs swiftly.
They all begin with the memory origin, employing surprise or novelty mechanisms to create intrinsic rewards that guide the exploration of the RL agent. While being so convenient and easy to use, two major issues have hindered the ability of the framework to explore effectively:
Detachment: lose track of interesting areas to explore.
Derailment: prevent it from utilizing previously visited states.
🧠 But what other alternatives could there be to overcome these issues?

Direct Exploration
In this section, we will explore a new form of exploration that is more direct and mechanical. While it requires additional complexity, it proves to be quite effective. 🧠 What is direct exploration? In short, it is a systematic approach where an agent revisits previously discovered states to explore new actions and areas, enhancing efficiency and effectiveness in sparse reward environments.
Under this new scheme, the role of memory is simplified to:
Storing past states.
Retrieving states to explore.
Replaying past experiences.
We will refer to the memory as "replay memory" to distinguish it from semantic and episodic memory concepts.

The effectiveness of the direct exploration framework heavily relies on the sampling strategy, which can generally be categorized into exploration-focused and performance-driven.
Replay Memory Focused on Exploration
One of the pioneering works that paved the way for the direct exploration framework is 👉Go-Explore [1], the first paper to achieve superhuman performance on Atari games.

According to the paper, memory, and simulators offer effective solutions to address the challenges of detachment and derailment mentioned earlier. Detachment, where an algorithm loses track of interesting areas to explore, can be mitigated by using memory to group similar states into cells. This approach is akin to a hash count mechanism. Each state is mapped to a cell, with each cell having a score that indicates its sampling probability.
On the other hand, derailment, where exploratory mechanisms prevent the algorithm from utilizing previously visited states, can be tackled using a simulator, although this is only suitable for Atari environments. The simulator samples a cell's state from memory and resets the agent's state to that of the cell. Throughout the exploration process, the memory is continually updated with new cells, ensuring that the agent remains on track and fully utilizes past experiences.
The basic workflow extends the direct exploration as follows
.")
Here, the replay memory stores three crucial elements: the state, the cell (corresponding to the state), and the cell's score. A higher cell score indicates a greater likelihood that the cell will be sampled for exploration from its state.
The cell is a compressed state representation, making storing efficient and informative against noise. The paper uses simple engineering tricks for the state-to-cell mapping process using downscaled cells with adaptive downscaling parameters to ensure robustness. It starts by grouping recent frames into cells and selecting hyperparameter values that optimize a specialized objective. This objective encourages frames to be distributed as uniformly as possible across cells, preventing the issues caused by overly non-uniform distributions. By avoiding excessive aggregation and insufficient aggregation of frames, the approach ensures balanced exploration and maintains tractability.
The probability of choosing a cell at each step is proportional to its count-based selection weight to enhance the selection of novel states:

The authors also incorporate domain knowledge by considering the number of horizontal neighbors to the cell present in the memory (h) and assigning a location bonus (k) for each cell (e.g., give a bonus at the location of the key):

In addition to the exploration phase, the authors propose a robustification phase (phase 2). The key idea here is to train from demonstrations: the backward algorithm positions the agent near the end of the trajectory. Then it runs PPO until the agent's performance matches that of the demonstration.
❌ One key limitation of Go-Explore: cell design is not obvious and requires detailed knowledge of the observation space, the dynamics of the environment, and the subsequent task
To address this limitation, 👉Latent Go-Explore [2] proposes a direct exploration mechanism without defining cell structures. It learns a latent representation distribution where states can be sampled from. The distribution is simultaneously learned with the exploration process, allowing the RL agent to refine its understanding of the environment in a more abstract and nuanced way. This concurrent learning ensures that the agent adapts and evolves its exploration strategy in real time.
A standout feature of Latent Go-Explore is its goal sampling method, which relies on a non-parametric density model of the latent space. This flexible approach allows the AI to focus on the most promising areas, enhancing exploration efficiency. By replacing traditional simulators with goal-based exploration, Latent Go-Explore directly pursues specific objectives, leading to more robust and versatile outcomes in dynamic environments. The workflow consists of 5 steps:
![Latent Go-Explore framework. Source: [2]](https://substackcdn.com/image/fetch/$s_!HtnA!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5fc1529c-a09a-4137-b5bf-8d1df1b55423_1137x336.png "Latent Go-Explore framework. Source: [2]")
Step 2 is one of the most important steps where the latent representations are learned. This process leverages ICM’s Inverse Dynamics and Forward Dynamics to predict the outcomes of actions, while Vector Quantized Variational Autoencoder (VQ-VAE [3]) helps in capturing and reconstructing intricate data patterns. These techniques work together to form a comprehensive representation of the states.
In Step 3, density estimation is employed to strategically sample goals. To ensure meaningful exploration, goals are selected at the edges of yet unexplored areas, promoting thorough investigation. These goals must be reachable, meaning they have been visited previously, ensuring feasibility. Additionally, a particle-based entropy estimator is used to calculate the density score and rank. Given the rank R, the sampling probability is:
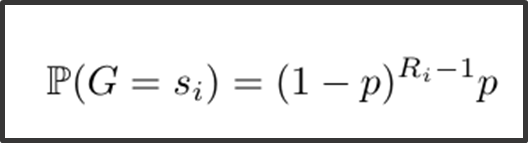
where the sampling distribution uses geometric law on the rank. p is a hyperparameter. The higher the rank (more dense), the less novel the sample is.
In Step 4, once the goal is defined, the agent employs goal-conditioned policy training to navigate toward it. This method involves training the agent's policy network to generate actions based explicitly on the specified goal state. Now the direct exploration framework does not require the simulator and can be used in any setting:

🧠 How to train a goal-directed policy? The basic idea is to train a policy to maximize the reach-goal rewards (achiever) and this policy is often jointly trained with another exploration policy (explorer) whose goal is to maximize the exploration rewards such as intrinsic motivation rewards. To reduce the number of interactions with real-world environments, a world model can be used to generate trajectories for the training of the two policies. This general goal-conditioned RL (GCRL) framework is illustrated below:

Given the GCRL framework, the effort now is on defending the goal to guide the Go-phase and Explore-phase. Instead of selecting goals at the frontier of previously explored states, as advocated in Latent Go-Explore, we can directly search for goals that promise the highest exploration rewards throughout the exploration phase [5]. In particular, the paper formulates a novel objective:

Here, we search for the goal g that maximizes the expected exploration values from reached goal sT. The authors simplify the formulation by using approximations:


The optimization process starts by randomly sampling N goal candidates (gk), from an initial distribution. These candidates are evaluated using the world model and the approximation exploration value for each goal Vk. After scoring each goal candidate, a Gaussian distribution is fitted based on the following rule:

which then will be used for the next sampling iterations. The method is called 👉Planning Exploratory Goals (PEG) and has shown promising results, evidenced by a vast range of exploration and higher goal-reach success rates:

Performance-based Replay Memory
The strategy for sampling goals can either encourage exploration, as discussed in previous papers or directly involve task performance. In the latter case, the aim is to sample states that lead to higher task returns.
One early and straightforward concept is 👉 Self-imitation Learning [6]. This idea centers on leveraging past successful experiences to significantly enhance an agent's learning process. By mirroring its own past good decisions, the agent ensures that effective strategies are reinforced and repeated. A key component of this approach is memory, which acts as a replay buffer to store the agent's previous experiences. This replay buffer allows the agent to revisit and learn from past interactions, thereby making more informed decisions over time.
In practice, the agent selectively learns to imitate state-action pairs from the replay buffer when the return from a past episode exceeds its current value estimate. This performance-based sampling prioritizes high-reward strategies, ensuring that the agent focuses on actions that have previously yielded better results. Specifically, if the return in the past is greater than the agent’s value estimate (R > Vθ), the agent replicates the same action in similar future states. This strategy consistently guides the agent towards choosing high-performing actions, optimizing its overall performance.
👀 It is important to note that performance-based sampling in this context is used to select data for training the policy, unlike direct exploration techniques that sample goals to initiate exploration. Despite this difference, the overall effect remains quite similar.
Recent works advocate for hybrid solutions combining performance and novelty aspects into goal-based exploration, leveraging replay memory to enhance the agent's ability to discover novel states. The principle is that by editing or augmenting trajectories stored from past experiences, the agent can generate new paths that lead to previously unvisited areas, thus initiating better exploration.
In the 👉Diverse Trajectory-conditioned Self-Imitation Learning (DTSIL) paper[7], This is achieved through a sequence-to-sequence model equipped with an attention mechanism, which effectively ‘translates’ a demonstration trajectory into a sequence of actions, forming a new trajectory. If the ending of the newly generated trajectory differs significantly from previous ones, it is inserted into the memory; otherwise, it is replaced with a trajectory that offers a higher return.
The agent samples these trajectories using a count-based novelty approach to ensure a diverse exploration of the state space.

To optimize its learning, the agent is trained with a trajectory-conditioned policy network πθ(at|e≤t,ot, g), which allows it to flexibly imitate any given trajectory g sampled from the buffer. The network is given a demonstration trajectory g and recursively predicts the next actions to imitate g. To facilitate the imitation process, a reward of 0.1 is assigned if the state closely resembles the demonstrated one. Further imitation encouragement is applied by introducing the action imitation loss:

These imitation strategies ensure that the agent can replicate effective paths while still adapting to new scenarios due to changes in current observations.
After completing the last (non-terminal) state in the demonstration, the agent is encouraged to perform random exploration by assigning a reward of zero. This encourages the agent to deviate from known paths and explore new possibilities, thus enhancing its overall learning and adaptation capabilities.
Causal Exploration
Imagine an RL agent tasked with picking up a key to open a door in a large room. Unfortunately, the agent spends most of its time wandering around the door but can't open it. If the agent understood that it needed the key to open the door, it wouldn't waste time near the door before obtaining the key. This scenario illustrates that better exploration requires an understanding of cause and effect, which can significantly improve the efficiency of the exploration process.

What is Causality?
Causality delves into the intricate relationship between cause and effect, seeking to uncover the fundamental questions of how we can identify and infer these connections. In the context of reinforcement learning, certain actions can lead to high or low rewards, such as picking up a key versus not picking it up. The state, a measurable context variable, influences both the action and the reward; for instance, the agent's current viewport as the state will allow the agent to take certain actions and receive certain rewards. Moreover, there are also confounding variables (U), which are unknown factors that affect both the action and the reward, such as the location of the door, outside of the viewport.
, Action (A), Reward (R), and Unknown (U).")
The Structure Causal Models (SCMs) framework, as introduced by Judea Pearl provides a structured approach to modeling causal relationships, using causal graphs to visually and mathematically represent the relationships between different variables. Formally, the relationship forms a causal graph G={V,E} where each vertex or node Vi is defined by:

where PA means the set of parental nodes. Understanding these relationships is crucial for the agent to make more informed decisions and optimize its actions for better outcomes. However, SCM is often unknown to the agent. Consequently, the agent may attempt to open the door before searching for the key, necessitating causal discovery to extract the SCM from observation data. In the case of SCM, it means given a set of nodes, we need to find:
Model Ui
The edges between the nodes, parameterized by structural parameter η (e.g., adjacency matrix)
The relation function fi, parameterized by functional parameter δ (e.g., neural networks)
Directly searching for SCM is not typically scalable due to the complexity of the causal graphs in RL.

👀 It is critical to find efficient alternative/approximating methods to discover causal relationships and leverage them for the agent's exploratory advantage.
Dependency Test
One way to simplify the causal discovery is to remove the unknown variable U from the graph. Then, we focus on a one-step transition graph as proposed in [8]:
States S is decomposed to N components (N entities)
Nodes: V = {S1, . . . , SN , A, S1’ , . . . , SN’}
Edges:
From S to S’: dynamics function
From S to A: policy function
From A to S’: action influence

Considering the assumption of local causal mechanisms, the impact tends to be localized and sparse. Specifically, for a given situation S=s, certain influences within the local causal graph GS=s may either exist or not. For instance, when the robot arm is far from the object, the action (A) primarily affects the state of the robot arm (S1), rather than the state of the object (S2). This variability highlights the nuanced nature of causal relationships within specific contexts, where the presence or absence of influences can significantly affect outcomes.
Under this assumption, the focus of causal discovery revolves around determining whether the agent is in control of the state of entity Sj given the current state s, i.e., 👉 Causal Action Influence framework [8]. This can be verified through a dependence test, specifically using Conditional Mutual Information (CMI). In particular, we measure the influence of the state s:

This quantity can be approximated as:

Neural networks can be used to estimate θ. In practice, since we are primarily concerned with the influence of the state s on a single final goal Sj, we use the score to characterize the state. This influence score can then serve as an intrinsic reward, encouraging the agent to visit highly influential states.
Potential Outcome
In causal discovery, we generally need to address the question: 🧠 When is an agent’s action “A = a” the cause of an outcome “B = b”? Besides the dependency test, we can answer by using the potential outcome framework, which contrasts the actual outcome with a hypothetical scenario where “A = a” did not occur. This approach requires knowledge of the normative or counterfactual world to make accurate assessments.
One paper in this field explores the effect disentanglement of the transition sub-graph, focusing on 👉 controllable effects [9]. It examines how the next state S’ depends on both the action A (which encodes the controllable effect) and the previous state S (which encodes the non-action or dynamic effect). The central question is: 🧠 is the next state primarily caused by the action taken, or is it merely coincidental? Here, S acts as a known confounder, a common scenario in stochastic or multi-agent environments.

What we observe is the total effect et(s,a)=s’-s, which represents the change in s′ from s. To measure the controllable effect ec(s, a), the authors adopt the potential outcome framework, proposing the following estimations:


Here, the difference in outcome when taking action a and other “normal“ action ã is used to estimate the controllable effect. To learn et, a neural network is trained to minimize the MSE loss:

As we can use the neural network to compute ec(s, a), we can learn ec distribution and sample ec as a goal as in the goal-conditioned RL (GCRL) framework presented earlier.
Structural Causal Model
Only recently has the use of SCM become available in aiding RL exploration. To make the causal discovery tractable, early works [10] are limited to variable/object causal graphs rather than encompassing the full scope of transition graphs. This is crucial in environments containing multiple objects where understanding causality between the objects is beneficial for exploration. For instance, consider an agent combining wood and stone to craft an axe, the agent needs to figure out that “axe” has causal edges to “wood” and “stone”. This knowledge will enable the agent to look for wood and stone instead of other things when tasked with crafting an axe.

❌ This approach faces a clear limitation: it assumes the complete set of objects or environmental variables is known, meaning the environment can be fully factorized.
In response, a recent paper introduced 👉 Variable-Agnostic Causal Exploration for Reinforcement Learning (VACERL) [11], a novel framework that incorporates causal relationships to drive exploration without specifying environmental causal variables. The author uses attention mechanisms to automatically identify crucial observation-action steps associated with key variables. It then constructs a causal graph linking these steps, guiding the agent towards observation-action pairs with greater causal influence on task completion. Finally, the causal graph can be used to generate intrinsic rewards or goals for intrinsic motivation or GCRL framework, respectively.
")
Since the environment is not assumed to be factorized, a naive approach might think that any states or state-action pairs in trajectories represent environmental variables (EV). However, this would result in an overly complex causal graph. The crucial phase, therefore, is to detect key observation-action pairs, and consider these limited sets of important pairs as EV, thereby reducing the variable space. To this end, the authors train a Transformer to predict the final goal state. The Transformer (TF) takes past observations from the trajectory k as input and aims to output the goal observation (step T):
The objective is to minimize the MSE error:
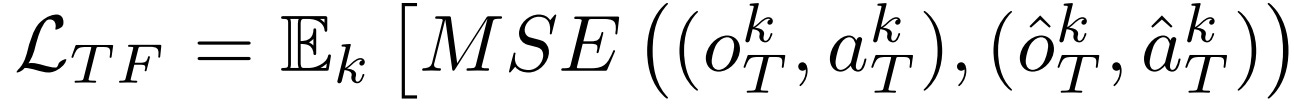
The authors then use the attention weights to filter out state-action pairs that are not important to the goal (those with low attention scores). Only M important pairs are stored in the ”crucial observation-action steps” set (SCOAS).
Next, in the second phase, the causal relationships among the M steps are identified using a 2-step SCM discovery algorithm [12]. The main idea is to optimize the functional parameter δ and the structural parameter η within the SCM framework through a flexible, two-phase iterative process. This involves alternately fixing one parameter while updating the other. Starting with random initialization, both parameters are trained using data induced from the set SCOAS. Here, the approach is based on the principle that a “cause” step must come before its “effect” step. Consequently, the function fδ is represented by a neural network tasked with predicting the step at timestep t using the sequence of steps leading up to it. The training objective is to minimize the MSE error between the prediction and the true data:

To find η representing causal influence from one node in the causal graph to another, the authors fix δ and optimize η by updating the causal influence from a node Xj to Xi as follows:

where:

where ϕcausal is the causal threshold. By iteratively updating the SCM’s parameters, the algorithm converges and provides a causal graph for the later phase. Given the graph, we can generate intrinsic rewards or set goals to aid exploration.
❌ One limitation of the approach is found in Phase 1, where knowing the goal state is necessary to train the Transformer. This dependency on successful trajectories implies that sufficient exploration is needed, potentially resulting in inefficiencies due to the high number of environment steps required to collect them.
References
[1] Ecoffet, Adrien, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, and Jeff Clune. "First return, then explore." Nature 590, no. 7847 (2021): 580-586.
[2] Quentin Gallou´edec and Emmanuel Dellandr´ea. 2023. Cell-free latent go-explore. In International Conference on Machine Learning. PMLR, 10571–10586.
[3] Van Den Oord, Aaron, and Oriol Vinyals. "Neural discrete representation learning." Advances in neural information processing systems 30 (2017).
[4] Russell Mendonca, Oleh Rybkin, Kostas Daniilidis, Danijar Hafner, and Deepak Pathak. Discovering and achieving goals with world models. In Advances in Neural Information Processing Systems, 2021.
[5] Hu, Edward S., Richard Chang, Oleh Rybkin, and Dinesh Jayaraman. "Planning Goals for Exploration." In The Eleventh International Conference on Learning Representations. 2022.
[6] Oh, Junhyuk, Yijie Guo, Satinder Singh, and Honglak Lee. "Self-imitation learning." In International conference on machine learning, pp. 3878-3887. PMLR, 2018.
[7] Yijie Guo, Jongwook Choi, Marcin Moczulski, Shengyu Feng, Samy Bengio, Mohammad Norouzi, and Honglak Lee. 2020. Memory-based trajectory-conditioned policies for learning from sparse rewards. Advances in Neural Information Processing Systems 33 (2020), 4333–4345.
[8] Seitzer, Maximilian, Bernhard Schölkopf, and Georg Martius. "Causal influence detection for improving efficiency in reinforcement learning." Advances in Neural Information Processing Systems 34 (2021).
[9] Oriol Corcoll, Raul Vicente. Disentangling Controlled Effects for Hierarchical Reinforcement Learning, CLeaR 2022
[10] Hu, X., Zhang, R., Tang, K., Guo, J., Yi, Q., Chen, R., ... & Chen, Y. (2022). Causality-driven hierarchical structure discovery for reinforcement learning. Advances in Neural Information Processing Systems, 35, 20064-20076.
[11] Nguyen H, Le H and Venkatesh S (2024), "Variable-Agnostic Causal Exploration for Reinforcement Learning", In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML-PKDD).
[12] Ke, N.R., Bilaniuk, O., Goyal, A., Bauer, S., Larochelle, H., Schölkopf, B., Mozer,
M.C., Pal, C., Bengio, Y.: Learning neural causal models from unknown interventions. arXiv preprint arXiv:1910.01075 (2019)