


Think Before You Speak: Reinforcement Learning for LLM Reasoning
Surveying New Frontiers in Reinforcement Learning for Language Models (Part 1)

Large Language Models (LLMs) have shown remarkable capabilities across a range of natural language tasks. Yet, when you give them a problem that needs a bit of careful thinking, like a tricky math question or understanding a complicated document, suddenly they can stumble. It's like they can talk the talk, but when it comes to really putting things together step-by-step, they can get lost.
🧠Why does this happen? Fundamentally, LLMs are stateless function approximators, trained to predict the next token in static datasets. This setup limits their ability to reflect, revise, or optimize their outputs during inference. In contrast, reasoning is inherently dynamic: it requires planning, adaptation, and sometimes backtracking, all things LLMs aren't naturally trained to do at test time.
In this blog series, we explore how Reinforcement Learning (RL) can be used to bridge that gap. Specifically, we will focus on test-time scaling and fine-tuning with RL. Instead of just training the model once with supervised training and hoping for the best, this approach lets the AI learn and improve while trying to figure things out. It's like allowing the model to learn from its mistakes in real time, which could be a game-changer for getting these models to truly reason effectively.
Sounds promising? In today’s post, we’ll kick things off by reviewing the core problems and foundational concepts behind using Reinforcement Learning to enhance LLM reasoning.

Table of Contents
What is Reasoning?
Reasoning is the process of making logical inferences, often involving multiple steps and abstract relationships. In human cognition, it comes in various forms:
Deductive Reasoning: Draws specific conclusions from general rules.

Deductive reasoning example: All humans are mortal → Socrates is human → Socrates is mortal. Source: OpenAI’s Sora. Inductive Reasoning: Generalizes from specific examples.
Example: Every swan I’ve seen is white → All swans must be white.Analogical Reasoning: Applies knowledge from one domain to another.
Example: An apple falling → leads to the idea of gravity → applies to other objects.Abductive Reasoning: Infers the most plausible explanation given incomplete data.
Example: Patient has fever and cough → possibly the flu.Causal Reasoning: Understands cause-and-effect relationships.
Example: Touching fire causes pain → Fire is dangerous.

Reasoning Concept Extension
Beyond the classical definitions of reasoning above, many real-world tasks require this kind of deeper cognitive process:
Planning: Choosing a sequence of actions to reach a goal (e.g., writing code, solving puzzles, or navigating a city).
Multi-agent Cooperation: Requires understanding others’ goals and intentions to coordinate effectively—think negotiation, team problem solving, or collaborative writing.
Visual/Spatial Reasoning: Inferring relationships from images, diagrams, or physical layouts—key in robotics and document understanding.
Logical Reasoning: Applying formal logic, e.g., deducing outcomes from a rule set, which is useful in law, security, and theorem proving.
Math/Physics/Chemistry: These domains require symbolic manipulation and consistency over multiple steps, beyond what most LLMs can handle reliably.
Given that, we can state a generic definition of reasoning:
👀 Reasoning involves any task that requires a multi-step process to reach a conclusion or achieve a goal.
Why Multi-Step Reasoning Is Hard
Multi-step thinking is often regarded as a defining characteristic of human intelligence—a key factor that sets us apart from other animals and even today’s most advanced AI systems.
Animals excel at instinctive or reactive behaviors such as hunting, navigating, or solving simple puzzles, but they cannot generally chain together long sequences of abstract thoughts or delayed subgoals.
Humans, on the other hand, can imagine complex future scenarios, revise plans mid-way, and build abstract models of the world. This is what enables scientific discovery, strategic planning, and deep reasoning.

To support this kind of intelligence, the brain (and AI systems that aim to replicate it) requires several foundational capabilities:
Working Memory: Holding Ideas in Mind
Multi-step reasoning depends on working memory. It’s like our brain’s mental scratchpad for tracking intermediate results, goals, and hypotheses.
Imagine doing long division or solving a logic puzzle.
At each step, you must retain partial results and update them as you proceed.
LLMs often struggle here because their context window is fixed and their state is reset between turns.
Without robust working memory, an agent cannot reason across steps, and thus, it forgets too quickly or becomes incoherent.
Semantic Memory: Knowing the World
Beyond short-term memory, reasoning also requires access to semantic memory, i.e., our long-term knowledge of facts, concepts, and cause-and-effect relationships.
To reason effectively, you must ground your logic in prior knowledge: What causes what? What’s typical or anomalous?
For LLMs, this means integrating pretrained world knowledge and external tools like retrieval systems.
Effective reasoning demands not only thinking in steps, but thinking with knowledge.
Reasoning Skills: The Cognitive Toolkit
Finally, multi-step thinking is shaped by the aforementioned set of reasoning strategies the agent can apply:
Deduction (applying rules)
Induction (generalizing patterns)
Abduction (inferring explanations)
Analogy (transferring structures)
Causality (understanding interactions)
👀 Humans fluidly combine these modes, often unconsciously. Most current LLMs imitate the surface form of such reasoning but struggle to apply them flexibly and reliably—especially over long chains of logic.
🎮 Reasoning Quiz: Before going to the section where we examine LLMs’ reasoning capability, let’s try to solve a simple and classic reasoning riddle:
A very special island is inhabited only by knights and knaves. Knights always tell the truth, and knaves always lie. You meet 2 inhabitants: Zoey and Oliver. Zoey remarked, "Oliver is not a knight". Oliver stated, "Oliver is a knight if and only if Zoey is a knave".
🧠So, who is a knight and who is a knave?
A. Zoey is a knight, and Oliver is a knave.
B. Zoey is a knave, and Oliver is a knight.
C. Zoey is a knight, and Oliver is a knight.
D. Zoey is a knave, and Oliver is a knave.
If you find it too easy, congratulations, you're a strong reasoner! If not, don’t worry because this type of puzzle takes practice to master. You could ask a powerful LLM for the answer, but keep in mind: it might get it right not because it truly reasons well, but because it’s likely seen similar questions during training.
Why do LLMs Struggle?
Large Language Models (LLMs) are incredibly powerful at generating fluent text. But can they truly reason? Let’s now look at the current progress of LLMs on reasoning.
2024: The Year LLMs Seemed to Master Reasoning
In 2024, both open-source and closed-source LLMs showed remarkable gains in reasoning benchmarks, especially in mathematics, which is widely considered one of the most rigorous domains for testing true reasoning ability.
Here’s a snapshot of some milestones:
GSM8K
Focused on grade-school-level math problems, GSM8K was once a major challenge for LLMs. Now, many models reach near-human or superhuman performance.

MATH Dataset
High-school-level math competition problems (including algebra, geometry, and calculus). GPT-4, Claude, and Gemini showed impressive accuracy, solving problems that were previously inaccessible to earlier models.

AlphaGeometry
DeepMind’s AlphaGeometry system combined LLMs with symbolic solvers to tackle geometry problems from the International Mathematical Olympiad (IMO), which marks a feat once considered impossible without full symbolic reasoning.

ARC Challenge
LLMs in 2024 finally broke through previous plateaus on this challenging compositional reasoning benchmark.

Together, these results suggest that LLMs are no longer just pattern completers. On the other hand, they’re beginning to simulate structured reasoning, especially when aided by symbolic tools or planning modules.
🧠 But are they truly reasoning? Or just better at mimicking multi-step solutions from their training data?
It Is Not Genuine Reasoning
I have hardly ever known a mathematician who was capable of reasoning.
—Plato—
Despite these impressive results, we should pause before declaring LLMs as true reasoners. As Plato once noted, carrying out mathematical calculations is not the same as understanding or reasoning.
Much of what looks like reasoning today might be:
Memorization, not abstraction: Many benchmarks contain repeated patterns. LLMs often succeed by memorizing common templates or copying reasoning chains from training data, without truly understanding the task.
Brute-force scaling: High performance often comes from increasing model size, training data, or inference-time sampling (e.g., with large N in few-shot CoT prompting). This is less about cleverness and more about resource-powered trial-and-error.
Evaluation loopholes: Some benchmarks have leaked into training datasets. Others allow too much prompting flexibility, making it hard to tell whether models are actually generalizing or just matching formats they've seen before.
Failing under slight variations: Modify a few words or introduce slightly out-of-distribution problems, and many LLMs fall apart. This brittleness signals that models aren’t learning conceptual reasoning, but rather surface-level heuristics.
For example, researchers have tried to create a symbolic version of GSM8K with various options to modify the original reasoning problem to create OOD variants.

Just by modifying the “easy“ GSM8K, the researchers realize a huge drop in many LLMs, from small to big, from weak to strong:

Looking ahead, we observe that weaker LLMs are more easily misled by modified versions of GSM8K. Even large reasoning models like GPT-4 (o1) experience a significant performance drop, up to 17%, on GSM8K, which is typically regarded as a simple math benchmark.
Looking across the field, researchers have developed many ways to expose the failure modes of LLM reasoning, from constructing challenging benchmarks to injecting adversarial prompts that easily mislead the models. These approaches consistently show that current LLMs, despite their scale, often struggle with robust reasoning.

At the heart of the problem is a fundamental mismatch: Reasoning requires structured, multi-step inference, whereas LLMs are trained as next-token predictors, optimized for surface-level fluency, not for logical consistency or long-horizon planning.
This gap manifests in several ways, from sensitivity to rephrasings and distractors to failures in symbolic manipulation and mathematical generalization. Tasks like modified GSM8K, logic puzzles, or counterfactual QA make it clear that even advanced models can be easily fooled.
These insights are important, but rather than just diagnosing limitations, the real challenge is: 🧠How can we improve LLM reasoning?
About Reinforcement Learning (RL)
There are rumors that AGI can be achieved with RL. We don’t know yet, but if you look around, RL is at the center of some of the most exciting progress in AI today. It’s more than just a buzzword, and it’s rapidly becoming a core tool for training intelligent systems that go beyond pattern recognition.
The recent wave of success stories built on LLMs, from OpenAI’s ChatGPT to Claude, Gemini, and others, has rekindled interest in RL as a key driver of advanced capabilities. The 2024 Turing Award was awarded for foundational contributions to deep reinforcement learning, solidifying its role in shaping modern AI.

And the trend continues: models like DeepSeek-R1, fine-tuned directly with RL, are pushing boundaries on reasoning benchmarks without relying on human imitation data.
Why RL Makes Sense for LLMs
Reinforcement Learning is a general and powerful learning framework that fits naturally with the challenges faced in aligning and improving LLMs:
Limited Ground-Truth Labels: LLMs often operate in domains where supervised data is scarce or expensive. RL allows models to learn from rewards instead of requiring gold-standard answers.
Structured Outputs: Tasks like reasoning, code generation, or multi-step planning involve structured and sequential outputs. RL is well-suited to optimize such trajectories.
Online and Active Learning: Unlike static training, RL supports interactive learning, where models improve by exploring actions, receiving feedback, and refining behavior over time.
While supervised learning helps LLMs imitate, RL helps them improve, optimizing toward what we want, even when it's hard to define explicitly. Before going any further, let’s learn some RL basics.
Reinforcement Learning: A Quick Primer
At its core, Reinforcement Learning (RL) is a learning paradigm where an agent learns to make decisions by interacting with an environment. On each step, the agent:
Takes an action a
Receives a reward r
Moves to a new state s

The goal of the agent is to learn a policy — a strategy for selecting actions — that maximizes the cumulative reward (often called the return, R) over time.
This trial-and-error learning process allows the agent to improve its behavior without needing ground-truth labels for every decision. It learns what to do based on feedback signals rather than direct supervision.
LLMs are typically trained using supervised learning or next-token prediction, which is great for mimicking human-like text, but not enough for deep reasoning. Here’s where RL comes in:
In reasoning tasks, there's often no single correct next token, but rather a set of steps that lead to the right conclusion.
We want LLMs to explore different reasoning paths, evaluate outcomes, and improve based on feedback, just like an RL agent.
Especially during test-time reasoning, we can use RL-inspired methods to search for better reasoning paths, refine outputs, and optimize for utility (e.g., correctness, coherence).
In this setting, the LLM becomes the agent, the reasoning task forms the environment, and rewards reflect how good a response is, whether based on logic, task success, or external feedback. Other RL components can be designed as follows.
🗽State = the current prompt or context
In the LLM setting, the state is typically the current sequence of tokens or the prompt plus anything the model has generated so far.
Example: If the LLM is solving a math problem step by step, then after each step, the state includes all the prior reasoning steps and the original question.
The state evolves with each new token or thought the model generates.
🛠️ Action = the next token or reasoning step
The action is the next token or next reasoning operation chosen by the LLM.
This could be a natural language token, a symbolic step in a proof, or even selecting a tool or subroutine to call.
In test-time reasoning, actions might include choosing between different intermediate paths or selecting which sub-question to answer next.
🔁 Putting it together:
At each step:
The LLM observes the current state (what it has "seen" and said so far),
Chooses an action (the next thing to say or do),
And transitions to a new state (the updated context).
This process continues until the model completes its response, or hits a stopping condition like generating an answer or reaching a maximum length. By treating reasoning as an RL problem, we unlock the ability to improve LLMs with feedback, optimization, and search, all essential ingredients for intelligent behavior. More importantly, we can leverage the rich literature of RL algorithms to upgrade LLMs.
Two Core RL Approaches: Q-Learning and Policy Gradient
To make an agent reason well, we want it to learn an optimal policy as a way to choose actions that maximize future rewards. There are two major families of methods in RL that help us do this: value-based and policy-based approaches.
Q-Learning: Learn the Value of Actions
The idea behind Q-learning is to learn the value of taking a certain action in a given state. Specifically, we estimate the Q-value function:
This represents the expected future reward if the agent starts in state s, takes action a, and then follows the optimal policy. There's also the state-value function:
Once we’ve learned Q(s,a), we can act greedily:
Choose a=argmaxaQ(s,a)
Or use ε-greedy: mostly pick the best action, occasionally explore
👀 For LLMs: This could mean estimating how useful a token or reasoning step is in a given context and learning to pick the highest-value continuation.
Policy Gradient: Directly Optimize the Policy
While Q-learning focuses on learning value functions first, policy gradient methods go straight for the policy. We define a parameterized policy πθ(a∣s), and directly optimize for the expected return:
To improve the policy, we compute gradients:
This tells us how to change the model’s parameters to increase the expected reward, essentially, how to fine-tune it toward better behavior.
In any case, Q-Learning or Policy Gradient, we need to make sure a good exploration-exploitation strategy to collect the data for training:

The choice of taking action is not only about making a good action, but also exploring other opportunities that potentially achieve a better outcome. To understand deeper, let’s look at two powerful ideas: UCB Bandits and Monte Carlo Tree Search (MCTS).
Upper Confidence Bound (UCB): The Exploration-Exploitation Trade-off
In many real-world settings (including prompting LLMs), we face uncertainty:
🧠 Should we exploit the best-known response, or explore new reasoning paths?
UCB (Upper Confidence Bound) tackles this by balancing two objectives:
Favoring actions with high average rewards
Encouraging exploration of less-tried actions
The classic UCB formula for choosing an action a is:
Q(a): The estimated value of taking action a, estimated as the average reward from arm a
n: Total number of trials
na: Number of times arm a has been chosen
c: Exploration factor
👀 If you want to know more about the derivation of the UCB formula, please refer to my past posts.
Monte Carlo Tree Search (MCTS): Planning Through Simulation
MCTS is a powerful planning algorithm useful when we can simulate interactions with the environment, making it ideal for test-time or online planning.
It enables multi-step lookahead by treating the decision-making process as an ExpectiMax tree:

The MCTS Loop: Four Key Steps
Selection: Traverse the current search tree from root to leaf using a policy like UCB to balance exploration and exploitation.

Expansion: Add a new child node (state) to the tree where a previously unvisited action is taken.


Simulation: Simulate or “roll out” from the new node to the end of the episode using a default (rollout) policy to estimate reward.
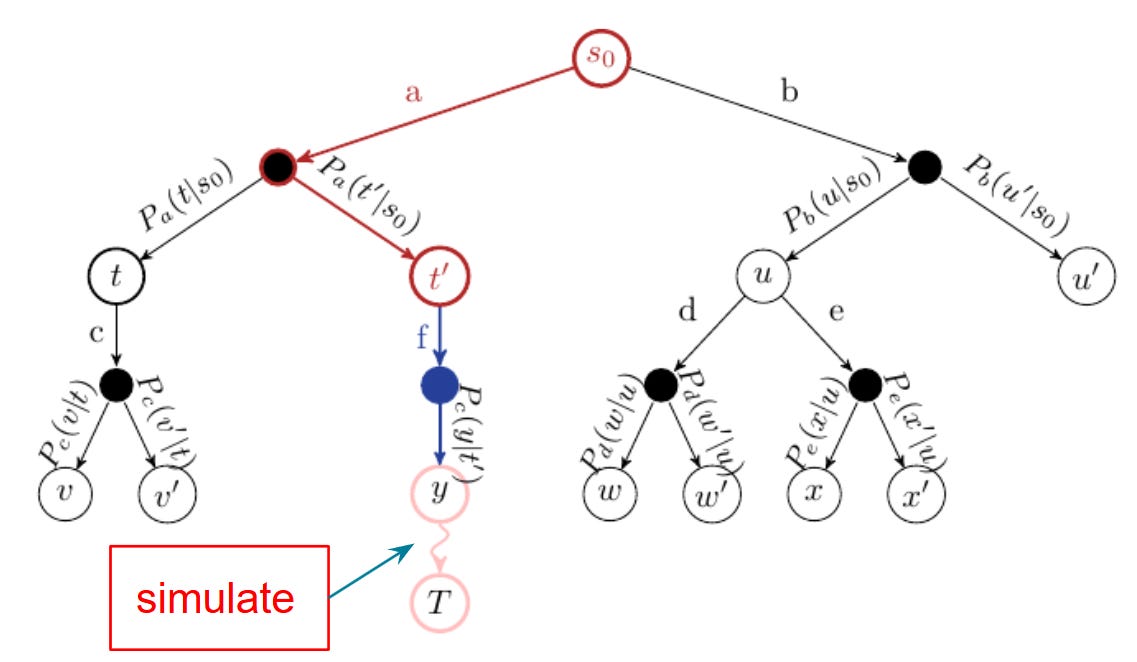
Backpropagation: Propagate the result of the simulation back up the tree, updating the value estimates of all visited nodes.

RL Achievements
Thanks to these tools, RL is proven to be effective in many areas. Before we dive deeper into how RL can enhance reasoning in LLMs, let’s review the milestones that brought RL to the center of modern AI.
Pre-LLM Era: RL Breakthroughs in Games
DQN [3]: Developed by DeepMind, DQN combined Q-learning with deep neural networks and achieved superhuman performance on Atari games, marking the first time deep RL could learn complex control policies directly from pixels.
AlphaGo [4]: Powered by Monte Carlo Tree Search (MCTS) and policy/value networks, AlphaGo made history by defeating world champion Go players. Go, with its immense search space and strategic depth, was long considered out of reach for AI. AlphaGo proved that multi-step planning + simulation-based RL could master even the most complex environments.
These achievements demonstrated that RL is a general and powerful learning mechanism, capable of solving hard problems where expert labels are scarce and long-term planning is key.
RL Meets Language Models
ChatGPT & RLHF (Reinforcement Learning from Human Feedback [5]): OpenAI's ChatGPT popularized RLHF, which fine-tunes large language models using human preferences as feedback. This approach uses policy gradient methods to optimize the model's behavior based on what humans find helpful or truthful. RLHF was the first technique to make LLMs reliably align with human intent, leading to the first wave of useful AI assistants that outperform humans on many general NLP benchmarks.
RL for prompt optimization [6]: Instead of handcrafting prompts or searching over static templates, RL allows us to learn a prompting policy that maximizes a downstream reward, such as accuracy, helpfulness, or user satisfaction. This is especially powerful in settings where the ideal prompt may vary per input or task.
What’s Next: RL for LLM Reasoning
As reasoning demands more:
Planning ahead
Structured multi-step inference
Consistency and goal-directed thinking
So it’s no surprise that RL is being revisited for improving the reasoning and dynamic decision-making of LLMs. In the next post, we’ll dive into how specific RL methods are being adapted to improve LLM reasoning, both during inference and training.
References
[1] Li, Chen, Weiqi Wang, Jingcheng Hu, Yixuan Wei, Nanning Zheng, Han Hu, Zheng Zhang, and Houwen Peng. "Common 7b language models already possess strong math capabilities." arXiv preprint arXiv:2403.04706 (2024).
[2] Mirzadeh, Seyed Iman, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models." In The Thirteenth International Conference on Learning Representations, 2024.
[3] Mnih, V., Kavukcuoglu, K., Silver, D. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015).
[4] Silver, D., Huang, A., Maddison, C. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016).
[5] Ouyang, Long, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744.
[6] Do, Dai, Quan Tran, Svetha Venkatesh, and Hung Le. "Large Language Model Prompting with Episodic Memory." In ECAI. 2024.